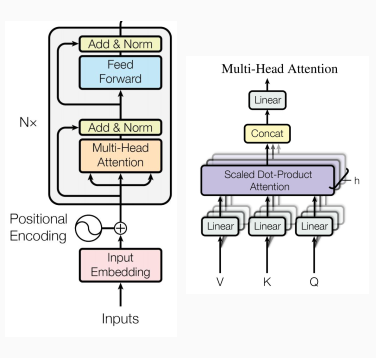
BERT模型的输入由三部分得到,token embdding, segment embedding, position embedding。
token embedding
对于所有文字来说,计算机都是无法理解的,需要转化为浮点向量或者整型向量。BERT采用的是WordPiece tokenization,是一种数据驱动的分词算法,他以char作为最小的粒度,不断地寻找出现最多以char为单位组成的token,之后将word进行分词,分为一个一个的token。比如ing这个会经常出现在英文当中,所以WordPiece 会吧”I am playing the computer games”分为”I am play ##ing the computer games”。为了解决OOV问题。词表中有30522个词。
classBertEmbeddings(nn.Module): """Construct the embeddings from word, position and token_type embeddings.""" def__init__(self, config): super().__init__() self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id) self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size) self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load # any TensorFlow checkpoint file self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps) self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
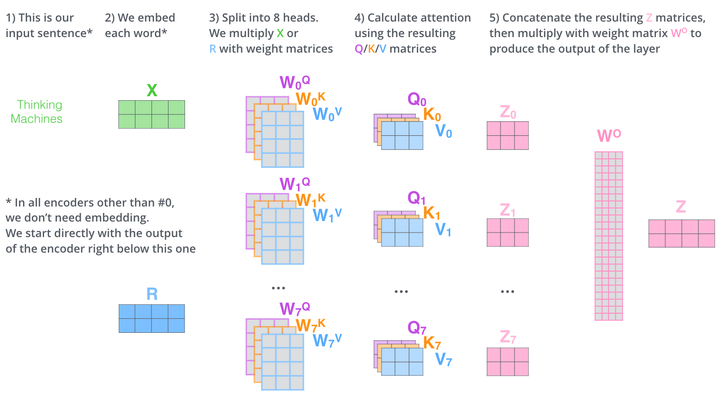
classBertSelfAttention(nn.Module): def__init__(self, config): super().__init__() if config.hidden_size % config.num_attention_heads != 0andnothasattr(config, "embedding_size"): raise ValueError( "The hidden size (%d) is not a multiple of the number of attention " "heads (%d)" % (config.hidden_size, config.num_attention_heads) )
# If this is instantiated as a cross-attention module, the keys # and values come from an encoder; the attention mask needs to be # such that the encoder's padding tokens are not attended to. if encoder_hidden_states isnotNone: mixed_key_layer = self.key(encoder_hidden_states) mixed_value_layer = self.value(encoder_hidden_states) attention_mask = encoder_attention_mask else: mixed_key_layer = self.key(hidden_states) mixed_value_layer = self.value(hidden_states)
# Take the dot product between "query" and "key" to get the raw attention scores. attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) attention_scores = attention_scores / math.sqrt(self.attention_head_size) if attention_mask isnotNone: # Apply the attention mask is (precomputed for all layers in BertModel forward() function) [1,1,1,0,0] -> [0,0,0,-10000,-10000] attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities. attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might # seem a bit unusual, but is taken from the original Transformer paper. attention_probs = self.dropout(attention_probs)
# Mask heads if we want to if head_mask isnotNone: attention_probs = attention_probs * head_mask